![SEO optimization] website robots.txt fill in the recommendations - Xiaoqi notes](https://www.snswm.com/wp-content/uploads/2022/03/截屏2022-03-04-02.10.42.png)

Search engine spiders visit the site will be the first to visit robots.txt file, robots.txt is used to guide the search engine spiders are prohibited from crawling the site certain content or only allowed to crawl those content, placed in the site root directory.
- User-agent Indicates which spider the following rules apply to.
*represent all #comment- Disallow denotes a file or directory that is forbidden to be crawled, and must be written on one line each, separately.
- Allow indicates the files or directories that are allowed to be crawled, each line must be written separately.
- Sitemap denotes the XML map of the site, note the capitalization of S.
The following indicates that all search engine spiders are prohibited from crawling any content
User-agent: *
Disallow: /
The following indicates that all search engine spiders are allowed to crawl any content
User-agent. *
Disallow.
meta robots
If you want the URL to not appear in search results at all, set up meta robots
<meta name="robots" content="onindex,nofollow">
The above code means: disable all search engines from indexing this page and disable tracking links on this page.
Of course there are other types of content, but support varies from browser to browser, so they are ignored here.
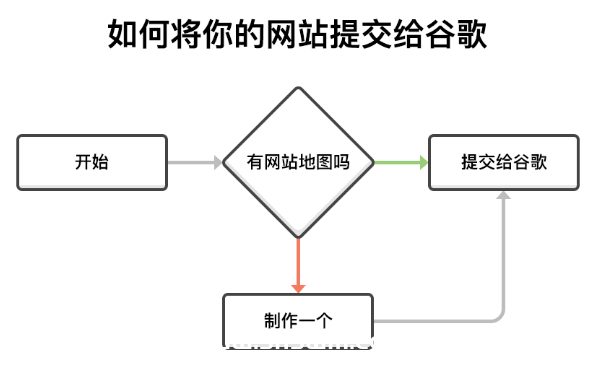

![SEO Basics] Keyword Definition and Classification - Xiao Qi Notes](https://www.snswm.com/wp-content/uploads/2022/03/网站关键词-500x320.png)
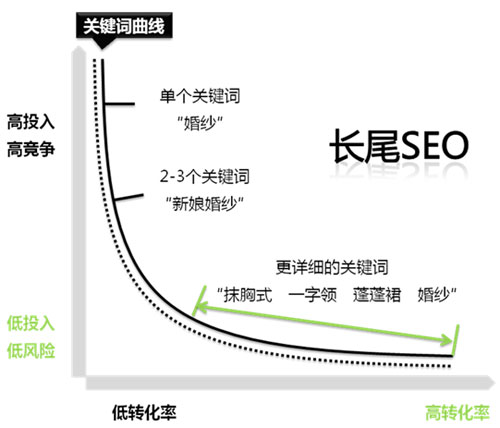
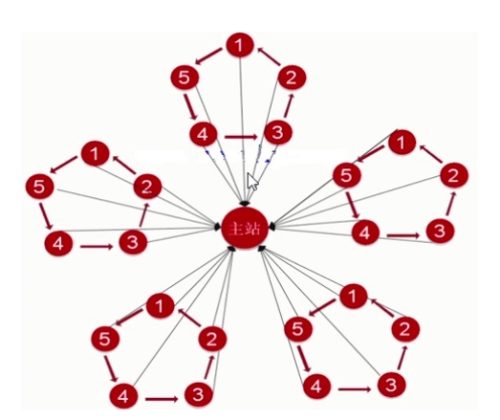
![SEO] TDK Optimization Suggestions - Xiaoqi Notes](https://www.snswm.com/wp-content/uploads/2022/03/seo-500x381.png)
![[Black Apple Installation Tutorial] macOS 12 Monterey Original OC Boot - Xiaoqi Notes](https://www.snswm.com/wp-content/uploads/2022/05/image-13.png)


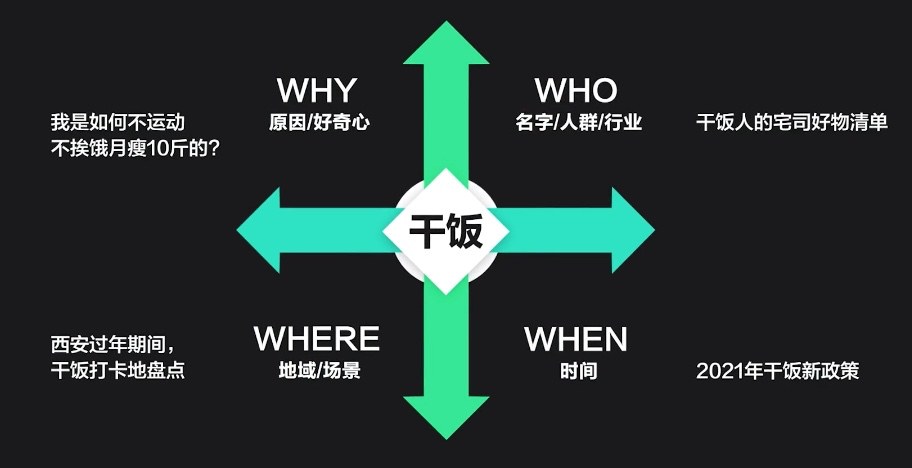

No comments